An audio transcription app based on machine learning automatically converts spoken words from an audio recording into written text using machine learning algorithms trained on large datasets of speech data .These apps can handle different accents and speaking styles,save time and effort,and provide a high level of accuracy and flexibility.
This project aims to build an app that transcribes audio files of various tones and styles into text using a deep learning approach that can correctly predict the user's description of the message in the expected emotion and tone modulation.
Tech stack -
-
Tensorflow - It is one of the most famous libraries for working with Machine Learning and Artificial Intelligence.
-
Keras - One of the best libraries that provides a python interface for working with artificial neural networks
- Audio Analysis Library Librosa - is a python package for music and audio analysis. It provides the building blocks necessary to create music information retrieval systems.
- Python Web Framework FLASK - Flask is used for developing web applications using Python, implemented on Werkzeug and Jinja2. Advantages of using Flask framework are: A built-in development server and a fast debugger are provided.
-
Kaggle - as virtual machine
-
HTML,CSS,Javascript - For designing the web application, that includes both frontend and backend
-
Python- Python becomes the most important multipurpose programming language for AI/ML data manipulation and implementation.
- Pandas, Numpy, Matplotlib - These data analysis and visualization libraries build the base of exploratory data analysis, like transforming the training testing and validation sets.
DataSet Used -
The LJ Speech Dataset
This is a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. A transcription is provided for each clip. Clips vary in length from 1 to 10 seconds and have a total length of approximately 24 hours.
The texts were published between 1884 and 1964, and are in the public domain. The audio was recorded in 2016-17 by the LibriVox project and is also in the public domain.
Methodology -
- We did preprocessing for a week which involved creation of input arrays and output labels, extracting important Mfccs, features necessary for training of the model.
- We made use of the Deep_speech2 model, improvising it according to our necessity.
- The model uses convolutional neural network layers which seems to be most effective for dealing with audio data manipulation.
- Further improvements were made for preparing a final model with a word error rate of 0.35
- The prepared model was integrated into the designed web application which used the flask framework to deploy it.
- We first get the audio file in wav format on the frontend part of our website which is stored on the wavfile of our backend and from there the file is feeded to the model to get the array and extract necessary features needed for prediction on the web page.
Working -
- PREPROCESSING - This is the primitive step of the project, the preprocessing of the audio data, i.e. applying the short term fourier transforms, extracting the mfcc, important features, Input data array manipulation using pandas is done.

- TRAINING THE MODEL -The model is trained on the LJ Speech Dataset making use of the convolutional neural network layers, the dataset is split into training set and test set, Batch Normalisation is used to speed up the training process and use higher learning rate. We adjusted the parameters of the optimizers and other static parameters along the training process for our best use.
- REDUCING THE LOSSES- We used the CTCLoss function to enhance the alignment and thereby reducing the losses by calculating the loss between an unsegmented time series and adjusting it accordingly.
- TESTING THE MODEL - The model is validated on the test set. A word error rate of less than 0.35 is achieved.
Snippets of working of web app-
- The frontend part of the app provides the user with a UI enabling them to upload an audio file(.wav type), and the user will get the prediction of the transcription of the audio file.
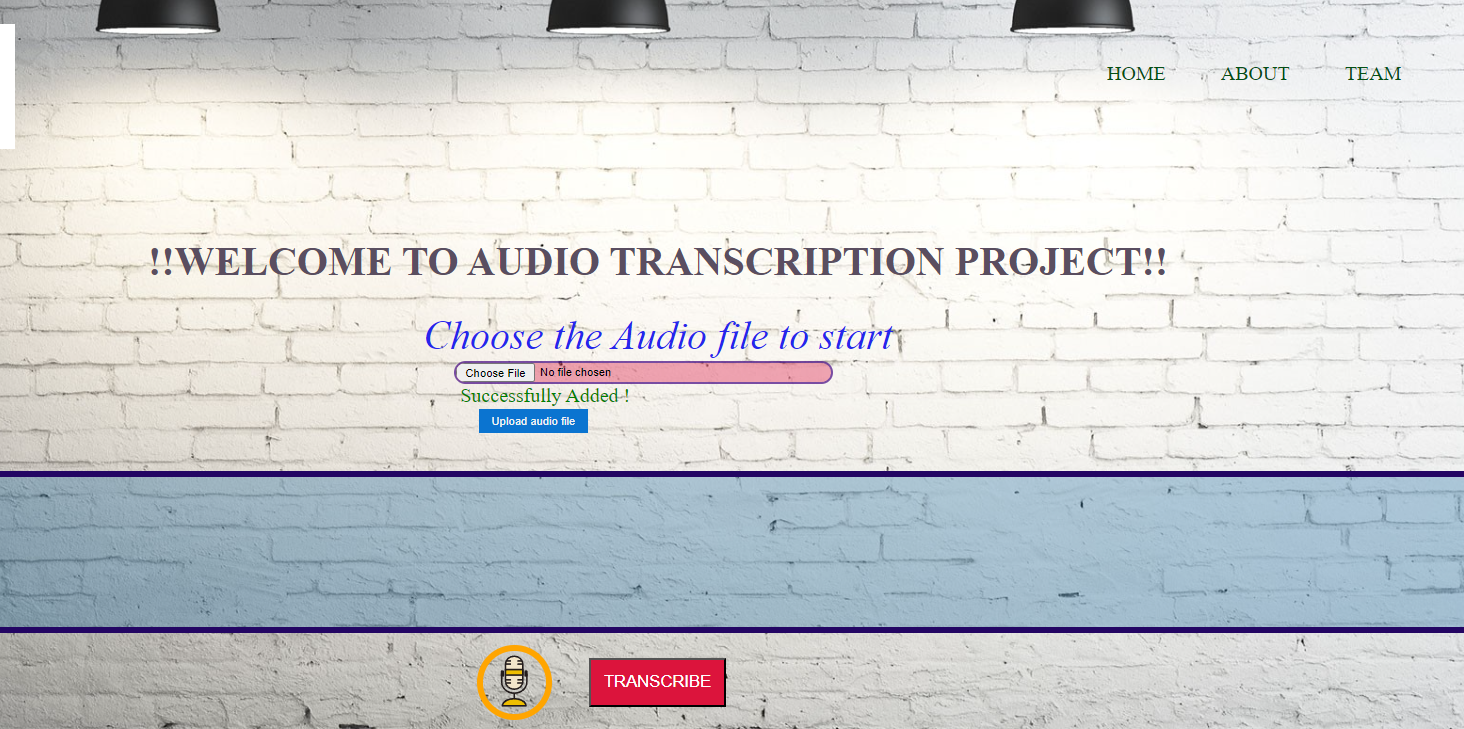
- After uploading the audio file we will get a message whether the file is successfully added or not.
- The uploaded audio file gets stored in the backend part of the website where it will be passed through a function for preprocessing to get an array which will be feeded to the model for prediction and following that transcription will be shown on the web app.


Resources -
1. Python
numpy,pandas and basic python documentation
W3Schools is best or you can refer to youtube for tutorials(readily available).
2. Librosa and audio processing
https://youtube.com/playlist?list=PL-wATfeyAMNqIee7cH3q1bh4QJFAaeNv0
other videos apart from the playlist on this channel.
3. ML and Deep Learning
Codebasics Channel for Both ML and Deep learning.
https://youtube.com/playlist?list=PLeo1K3hjS3uvCeTYTeyfe0-rN5r8zn9rw (for ML)
https://youtube.com/playlist?list=PLeo1K3hjS3uu7CxAacxVndI4bE_o3BDtO (for DL)
4. Documentation of packages like Tensorflow Keras,Librosa etc.
Real-life applications -
- Medicine: Doctors and nurses have to keep a large number of detailed records of interactions with patients, treatment plans, prescriptions, and more. With dictation services, they can verbally detail this information and have it automatically transcribed for greater efficiency.
- Social Media: If you’ve looked at Instagram or YouTube lately, you may have noticed some videos have captioning services. This is a new feature that autocaptions people as they speak using AI. While it may not always be fully accurate, it’s helping to provide greater accessibility and usability for users.
- Technology: Smartphones have had the talk-to-text feature in place for some time. As the name suggests, it lets you text someone through audio dictation rather than typing out the message.
- Law: In law, accurate documentation of court proceedings is fundamental to a case because accuracy can affect the outcome of that case. It’s also important for historical documentation to learn from or reference for future cases.
- Police Work: Audio transcription has numerous applications in police work, with likely more to come. It can be used for transcribing investigative interviews, evidence records, calls to the emergency line, body camera recorded interactions, and more. Much like with the law, the accuracy of these transcriptions can have a significant impact on court cases and people’s lives.
Challenges faced -
- One of the main challenges of this project was while doing loss correction for which we made a user defined CTC loss function before prediction and compiled with the model upload function and training of the model to get correct word error rate.
- There were other challenges like getting the model deployed using a web application for which we had to use the flask framework because of the python language used in the model.
- Problem of overfitting has still had to be tackled.Overall, this voice-to-text transcription project was a success, providing valuable insights into practical applications of audio transcription and its scope in present as well as future era.
Future Scope-
As of now of our website is capable of taking audio file as input and then transcribing it to text but in for further development we are going to incorporate microphone feature where the user can actually speak and the model will be able to predict it by recognizing different words and phrases based on their acoustic characteristics,such as pitch,volume,and rhythm and predict the appropriate transcription.
CONTRIBUTORS -
|
Name
|
Branch
|
Reg. no.
|
|
Kamal Ahmad
|
MECH
|
20213003
|
|
Amisha Singh
|
ECE
|
20215167
|
|
Vaishnav Anish
|
CSE
|
20214501
|
|
V Suhas
|
ECE
|
20215108
|
|
Kunwar Aridaman Singh
|
ECE
|
20215086
|
|
Divyanshi Singh
|
MECH
|
20213094
|
MENTORS -
- Purushotam Kumar Agrawal
- Anurag Gupta
- Ayush Singh Gour

